Hakyll setup

tlpl: Comment j’utilise hakyll. Abréviations, corrections typographiques, multi-language, utilisation d’index.html, etc…
Ce site web est fait avec Hakyll.
Hakyll peut être vu comme un cms minimaliste. D’une façon plus générale, il s’agit d’une bibliothèque qui facilite la création automatique de fichiers.
D’un point de vue utilisateur voici comment j’écris mes articles :
- J’ouvre un éditeur de texte (vim dans mon cas). J’édite un fichier markdow qui ressemble à ça :
Un titre de page
================
Un titre de chapitre
--------------------
Azur, nos bêtes sont bondées d'un cri.
Je m'éveille songeant au fruit noir de l'anibe dans sa cupule
véruqueuse et tronquée.
Saint John Perse.
### Titre 3
> C'est un blockquote.
>
> C'est un second paragraphe dans le blockquote
>
> ## C'est un H2 dans un blockquote- J’ouvre mon navigateur et je rafraichis de temps en temps pour voir les changements.
- Une fois satisfait, je lance un script minimal qui fait grosso modo un simple
git push. Mon blog est hébergé sur github.
A ne pas y regarder de trop près, on peut réduire le rôle d’Hakyll à :
Créer (resp. mettre à jour) un fichier html lorsque je crée (resp. modifie) un fichier markdown.
Bien que cela semble facile, il y a de nombreux détails cachés :
- Ajouter des métadatas comme des mots clés
- Créer un page archive qui contient la liste de tous les articles
- Gérer les fichier statiques
- Créer un flux rss
- Filtrer le contenu
- Gérer les dépendances
Le travail d’Hakyll est de vous aider avec tout ça. Commençons par expliquer les concepts basiques.
Les concepts et la syntaxe
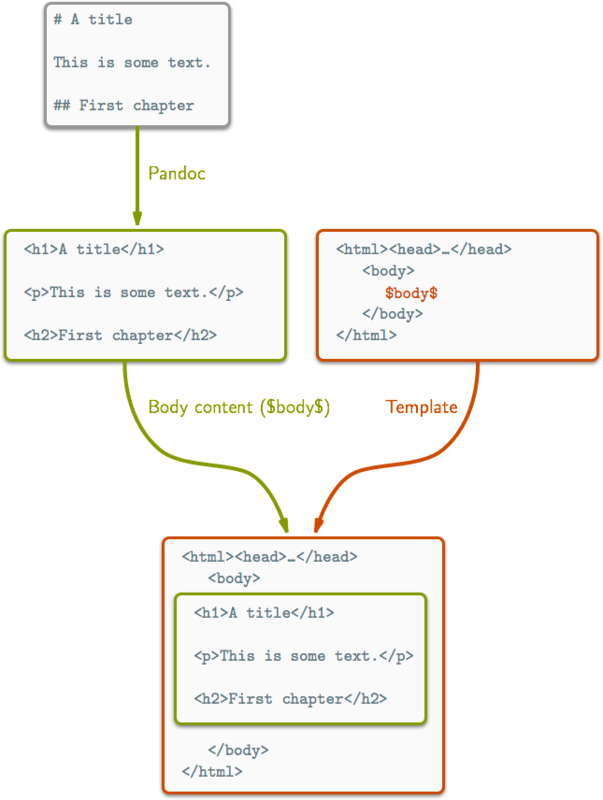
Pour chaque fichier que vous créer, il faut fournir :
- un chemin de destination
- une liste de filtres du contenu
Commençons par le cas le plus simple ; les fichiers statiques (images, fontes, etc…) Généralement, vous avec un répertoire source (ici le répertoire courant) et une répertoire destination _site.
Le code Hakyll est :
-- pour chaque fichier dans le répertoire static
match "static/*" do
-- on ne change pas le nom ni le répertoire
route idRoute
-- on ne modifie pas le contenu
compile copyFileCompilerCe programme va copier static/foo.jpg dans _site/static/foo.jpg. C’est un peu lourd pour un simple cp. Maintenant comment faire pour transformer automatiquement un fichier markdown dans le bon html?
-- pour chaque fichier avec un extension md
match "posts/*.md" do
-- changer son extension en html
route $ setExtension "html"
-- utiliser la librairie pandoc pour compiler le markdown en html
compile $ pandocCompilerSi vous créez un fichier posts/toto.md, cela créera un fichier _site/posts/toto.html.
Si le fichier posts/foo.md contient
le fichier _site/posts/foo.html, contiendra
Mais horreur ! _site/posts/cthulhu.html n’est pas un html complet. Il ne possède ni header, ni footer, etc… C’est ici que nous utilisons des templates. J’ajoute une nouvelle directive dans le bloc “compile”.
match "posts/*.md" do
route $ setExtension "html"
compile $ pandocCompiler
-- use the template with the current content
>>= loadAndApplyTemplate "templates/post.html" defaultContextMaintenant si templates/posts.html contient:
Maintenant notre ctuhlhu.html contient
<html>
<head>
<title>How could I get the title?</title>
</head>
<body>
<h1>Cthulhu</h1>
<p>ph'nglui mglw'nafh Cthulhu R'lyeh wgah'nagl fhtagn</p>
</body>
</html>C’est facile. Mais il reste un problème à résoudre. Comment pouvons-nous changer le titre ? Ou par exemple, ajouter des mots clés ?
La solution est d’utiliser les Contexts. Pour cela, nous devrons ajouter des metadonnées à notre markdown1.
Et modifier légèrement notre template :
Super facile!
La suite de l’article est en Anglais. Je la traduirai volontier si suffisamment de personnes me le demande gentillement.
Real customization
Now that we understand the basic functionality. How to:
- use SASS?
- add keywords?
- simplify url?
- create an archive page?
- create an rss feed?
- filter the content?
- add abbreviations support?
- manage two languages?
Use SASS
That’s easy. Simply call the executable using unixFilter. Of course you’ll have to install SASS (gem install sass). And we also use compressCss to gain some space.
match "css/*" $ do
route $ setExtension "css"
compile $ getResourceString >>=
withItemBody (unixFilter "sass" ["--trace"]) >>=
return . fmap compressCssAdd keywords
In order to help to reference your website on the web, it is nice to add some keywords as meta datas to your html page.
In order to add keywords, we could not directly use the markdown metadatas. Because, without any, there should be any meta tag in the html.
An easy answer is to create a Context that will contains the meta tag.
-- metaKeywordContext will return a Context containing a String
metaKeywordContext :: Context String
-- can be reached using $metaKeywords$ in the templates
-- Use the current item (markdown file)
metaKeywordContext = field "metaKeywords" $ \item -> do
-- tags contains the content of the "tags" metadata
-- inside the item (understand the source)
tags <- getMetadataField (itemIdentifier item) "tags"
-- if tags is empty return an empty string
-- in the other case return
-- <meta name="keywords" content="$tags$">
return $ maybe "" showMetaTags tags
where
showMetaTags t = "<meta name=\"keywords\" content=\""
++ t ++ "\">\n"Then we pass this Context to the loadAndApplyTemplate function:
match "posts/*.md" do
route $ setExtension "html"
compile $ pandocCompiler
-- use the template with the current content
>>= loadAndApplyTemplate "templates/post.html"
(defaultContext <> metaKeywordContext)☞ Here are the imports I use for this tutorial.
{-# LANGUAGE OverloadedStrings #-} import Control.Monad (forM,forM_) import Data.List (sortBy,isInfixOf) import Data.Monoid ((<>),mconcat) import Data.Ord (comparing) import Hakyll import System.Locale (defaultTimeLocale) import System.FilePath.Posix (takeBaseName,takeDirectory ,(</>),splitFileName)
Simplify url
What I mean is to use url of the form:
http://domain.name/post/title-of-the-post/I prefer this than having to add file with .html extension. We have to change the default Hakyll route behavior. We create another function niceRoute.
-- replace a foo/bar.md by foo/bar/index.html
-- this way the url looks like: foo/bar in most browsers
niceRoute :: Routes
niceRoute = customRoute createIndexRoute
where
createIndexRoute ident =
takeDirectory p </> takeBaseName p </> "index.html"
where p=toFilePath identNot too difficult. But! There might be a problem. What if there is a foo/index.html link instead of a clean foo/ in some content?
Very simple, we simply remove all /index.html to all our links.
-- replace url of the form foo/bar/index.html by foo/bar
removeIndexHtml :: Item String -> Compiler (Item String)
removeIndexHtml item = return $ fmap (withUrls removeIndexStr) item
where
removeIndexStr :: String -> String
removeIndexStr url = case splitFileName url of
(dir, "index.html") | isLocal dir -> dir
_ -> url
where isLocal uri = not (isInfixOf "://" uri)And we apply this filter at the end of our compilation
match "posts/*.md" do
route $ niceRoute
compile $ pandocCompiler
-- use the template with the current content
>>= loadAndApplyTemplate "templates/post.html" defaultContext
>>= removeIndexHtmlCreate an archive page
Creating an archive start to be difficult. There is an example in the default Hakyll example. Unfortunately, it assumes all posts prefix their name with a date like in 2013-03-20-My-New-Post.md.
I migrated from an older blog and didn’t want to change my url. Also I prefer not to use any filename convention. Therefore, I add the date information in the metadata published. And the solution is here:
match "archive.md" $ do
route $ niceRoute
compile $ do
body <- getResourceBody
return $ renderPandoc body
>>= loadAndApplyTemplate "templates/archive.html" archiveCtx
>>= loadAndApplyTemplate "templates/base.html" defaultContext
>>= removeIndexHtmlWhere templates/archive.html contains
And base.html is a standard template (simpler than post.html).
archiveCtx provide a context containing an html representation of a list of posts in the metadata named posts. It will be used in the templates/archive.html file with $posts$.
postList returns an html representation of a list of posts given an Item sort function. The representation will apply a minimal template on all posts. Then it concatenate all the results. The template is post-item.html:
Here is how it is done:
postList :: [Item String] -> Compiler [Item String]
-> Compiler String
postList sortFilter = do
-- sorted posts
posts <- loadAll "post/*" >>= sortFilter
itemTpl <- loadBody "templates/post-item.html"
-- we apply the template to all post
-- and we concatenate the result.
-- list is a string
list <- applyTemplateList itemTpl defaultContext posts
return listcreatedFirst sort a list of item and put it inside Compiler context. We need to be in the Compiler context to access metadatas.
createdFirst :: [Item String] -> Compiler [Item String]
createdFirst items = do
-- itemsWithTime is a list of couple (date,item)
itemsWithTime <- forM items $ \item -> do
-- getItemUTC will look for the metadata "published" or "date"
-- then it will try to get the date from some standard formats
utc <- getItemUTC defaultTimeLocale $ itemIdentifier item
return (utc,item)
-- we return a sorted item list
return $ map snd $ reverse $ sortBy (comparing fst) itemsWithTimeIt wasn’t so easy. But it works pretty well.
Create an rss feed
To create an rss feed, we have to:
- select only the lasts posts.
- generate partially rendered posts (no css, js, etc…)
We could then render the posts twice. One for html rendering and another time for rss. Remark we need to generate the rss version to create the html one.
One of the great feature of Hakyll is to be able to save snapshots. Here is how:
match "posts/*.md" do
route $ setExtension "html"
compile $ pandocCompiler
-- save a snapshot to be used later in rss generation
>>= saveSnapshot "content"
>>= loadAndApplyTemplate "templates/post.html" defaultContextNow for each post there is a snapshot named “content” associated. The snapshots are created before applying a template and after applying pandoc. Furthermore feed don’t need a source markdown file. Then we create a new file from no one. Instead of using match, we use create:
create ["feed.xml"] $ do
route idRoute
compile $ do
-- load all "content" snapshots of all posts
loadAllSnapshots "posts/*" "content"
-- take the latest 10
>>= (fmap (take 10)) . createdFirst
-- renderAntom feed using some configuration
>>= renderAtom feedConfiguration feedCtx
where
feedCtx :: Context String
feedCtx = defaultContext <>
-- $description$ will render as the post body
bodyField "description"The feedConfiguration contains some general informations about the feed.
feedConfiguration :: FeedConfiguration
feedConfiguration = FeedConfiguration
{ feedTitle = "Great Old Ones"
, feedDescription = "This feed provide information about Great Old Ones"
, feedAuthorName = "Abdul Alhazred"
, feedAuthorEmail = "[email protected]"
, feedRoot = "http://great-old-ones.com"
}Great idea certainly steal from nanoc (my previous blog engine)!
Filter the content
As I just said, nanoc was my preceding blog engine. It is written in Ruby and as Hakyll, it is quite awesome. And one thing Ruby does more naturally than Haskell is regular expressions. I had a lot of filters in nanoc. I lost some because I don’t use them much. But I wanted to keep some. Generally, filtering the content is just a way to apply to the body a function of type String -> String.
Also we generally want prefilters (to filter the markdown) and postfilters (to filter the html after the pandoc compilation).
Here is how I do it:
markdownPostBehavior = do
route $ niceRoute
compile $ do
body <- getResourceBody
prefilteredText <- return $ (fmap preFilters body)
return $ renderPandoc prefilteredText
>>= applyFilter postFilters
>>= saveSnapshot "content"
>>= loadAndApplyTemplate "templates/post.html" yContext
>>= loadAndApplyTemplate "templates/boilerplate.html" yContext
>>= relativizeUrls
>>= removeIndexHtmlWhere
applyFilter strfilter str = return $ (fmap $ strfilter) str
preFilters :: String -> String
postFilters :: String -> StringNow we have a simple way to filter the content. Let’s augment the markdown ability.
Add abbreviations support
Comparing to LaTeX, a very annoying markdown limitation is the lack of abbreviations.
Fortunately we can filter our content. And here is the filter I use:
abbreviationFilter :: String -> String
abbreviationFilter = replaceAll "%[a-zA-Z0-9_]*" newnaming
where
newnaming matched = case M.lookup (tail matched) abbreviations of
Nothing -> matched
Just v -> v
abbreviations :: Map String String
abbreviations = M.fromList
[ ("html", "<span class=\"sc\">html</span>")
, ("css", "<span class=\"sc\">css</span>")
, ("svg", "<span class=\"sc\">svg</span>")
, ("xml", "<span class=\"sc\">xml</span>")
, ("xslt", "<span class=\"sc\">xslt</span>") ]It will search for all string starting by ‘%’ and it will search in the Map if there is a corresponding abbreviation. If there is one, we replace the content. Otherwise we do nothing.
Do you really believe I type
each time I write LaTeX?
Manage two languages
Generally I write my post in English and French. And this is more difficult than it appears. For example, I need to filter the language in order to get the right list of posts. I also use some words in the templates and I want them to be translated.
First I create a Map containing all translations.
data Trad = Trad { frTrad :: String, enTrad :: String }
trads :: Map String Trad
trads = M.fromList $ map toTrad [
("changeLanguage",
("English"
, "Français"))
,("switchCss",
("Changer de theme"
,"Change Theme"))
,("socialPrivacy",
("Ces liens sociaux préservent votre vie privée"
,"These social sharing links preserve your privacy"))
]
where
toTrad (key,(french,english)) =
(key, Trad { frTrad = french , enTrad = english })Then I create a context for all key:
tradsContext :: Context a
tradsContext = mconcat (map addTrad (M.keys trads))
where
addTrad :: String -> Context a
addTrad name =
field name $ \item -> do
lang <- itemLang item
case M.lookup name trads of
Just (Trad lmap) -> case M.lookup (L lang) lmap of
Just tr -> return tr
Nothing -> return ("NO TRANSLATION FOR " ++ name)
Nothing -> return ("NO TRANSLATION FOR " ++ name)Conclusion
The full code is here. And except from the main file, I use literate Haskell. This way the code should be easier to understand.
If you want to know why I switched from nanoc:
My preceding nanoc website was a bit too messy. So much in fact, that the dependency system recompiled the entire website for any change.
So I had to do something about it. I had two choices:
- Correct my old code (in Ruby)
- Duplicate the core functionalities with Hakyll (in Haskell)
I added too much functionalities in my nanoc system. Starting from scratch (almost) remove efficiently a lot of unused crap.
So far I am very happy with the switch. A complete build is about 4x faster. I didn’t broke the dependency system this time. As soon as I modify and save the markdown source, I can reload the page in the browser.
I removed a lot of feature thought. Some of them will be difficult to achieve with Hakyll. A typical example:
In nanoc I could take a file like this as source:
And it will create a file foo.hs which could then be downloaded.
<h1>Title</h1>
<p>content</p>
<a href="code/foo.hs">Download foo.hs</a>
<pre><code>main = putStrLn "Cthulhu!"</code></pre>Nous pouvons aussi ajouter ces métadonnées dans un fichier externe (
toto.md.metadata).↩