tl;dr: Short introduction to Parsec for beginner.
- The html presentation is here.
() () () () () (
) (
) () () () () () () () () ()
Parsing
Latin pars (ōrātiōnis), meaning part (of speech).
-
analysing a string of symbols
-
formal grammar.
Parsing in Programming Languages
Complexity:
|
Splitting
|
CSV
|
Array, Map
|
|
Regexp
|
email
|
|
|
Parser
|
Programming language
|
|
Parser & culture
In Haskell Parser are really easy to use.
Generally:
-
In most languages: split then regexp then parse
-
In Haskell: split then parse
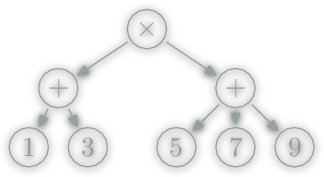
Parsing Example
From String:
(1+3)*(1+5+9)
To data structure:
Parsec
Parsec lets you construct parsers by combining high-order Combinators to create larger expressions.
Combinator parsers are written and used within the same programming language as the rest of the program.
The parsers are first-class citizens of the languages […]"
Haskell Wiki
Parser Libraries
In reality there are many choices:
|
attoparsec
|
fast
|
|
Bytestring-lexing
|
fast
|
|
Parsec 3
|
powerful, nice error reporting
|
spaces are meaningful
f x -- ⇔ f(x) in C-like languages
f x y -- ⇔ f(x,y)
Don’t mind strange operators (<*>, <$>).
Consider them like separators, typically commas.
They are just here to deal with types.
Informally:
toto <$> x <*> y <*> z
-- ⇔ toto x y z
-- ⇔ toto(x,y,z) in C-like languages
Minimal Parsec Examples
whitespaces = many (oneOf "\t ")
number = many1 digit
symbol = oneOf "!#$%&|*+-/:<=>?@^_~"
" \t " – whitespaces on " \t " "" – whitespaces on “32” “32” – number on “32”
– number on "